7. DATA LAKE
Data Lake¶
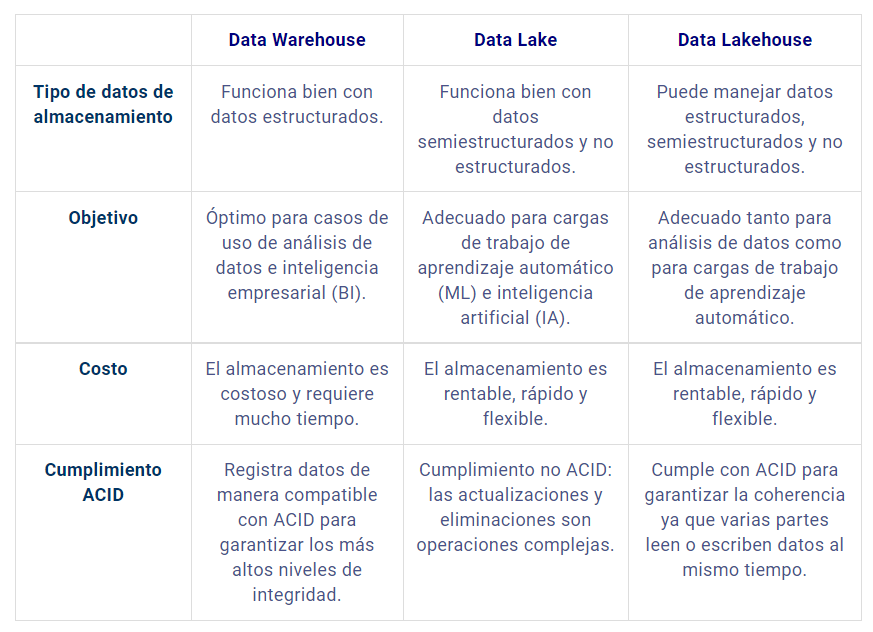
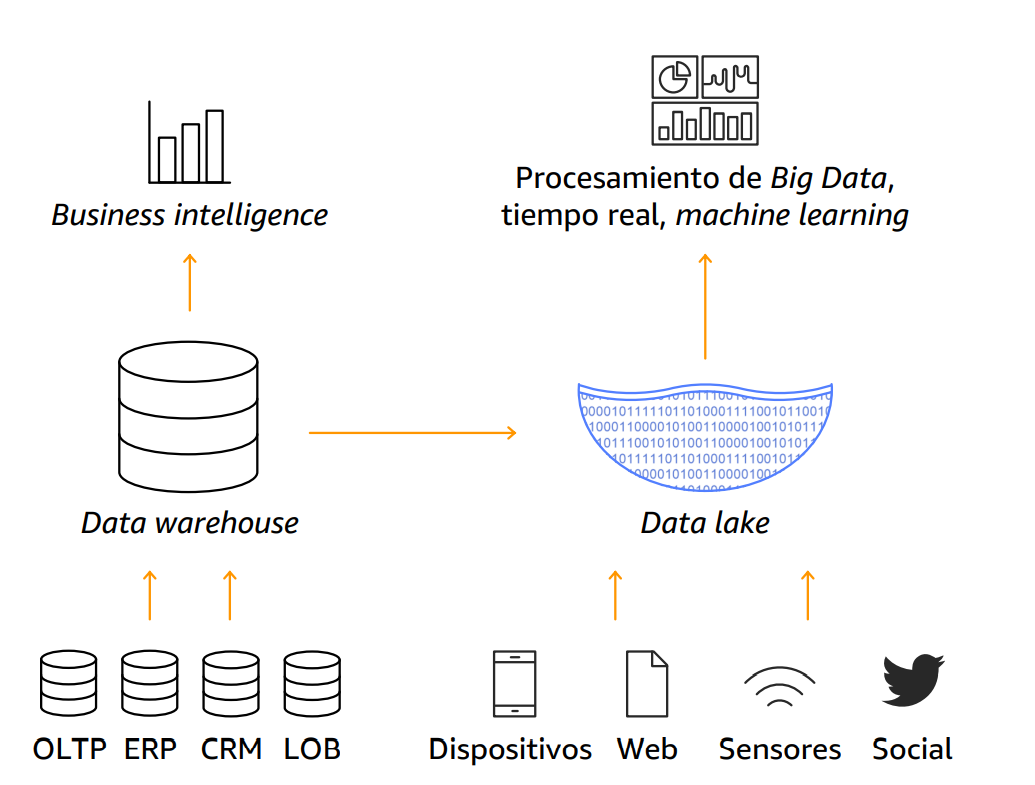
Un data lake o lago de datos es un repositorio centralizado que permite almacenar, compartir, gobernar y descubrir todos los datos estructurados y no estructurados de una organización a cualquier escala.
-
Los datos provienen de múltiples fuentes de datos variadas.
-
Los datos se guardan en su formato original, sin formatear ni procesar.
-
Los datos se organizan en carpetas, con diferentes niveles de acceso y tratamiento de la información.
-
Los datos son extraídos, cargados y transformados sólo cuando son necesarios, mediante procesos ELT.
-
Se recomienda guardar los datos en formato Parquet a excepción de la capa Raw.
Data Lake VS Data Warehouse ¶
-
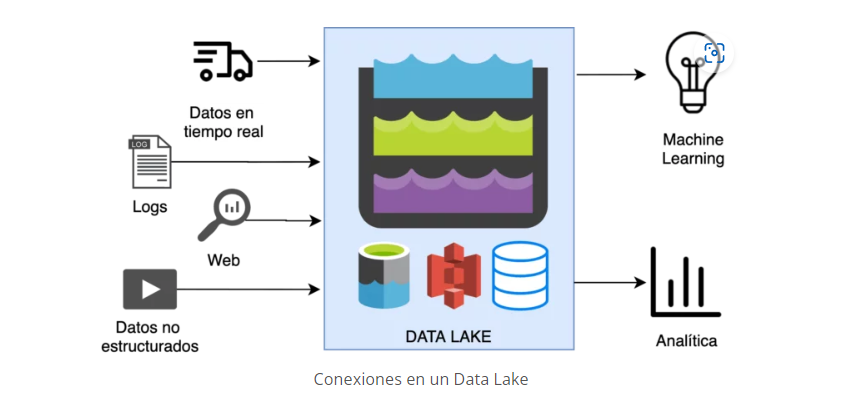
Los Data Warehouses son más lentos y complejos de implementar que los Data Lakes.
-
El Data Lake permite tener una gran capacidad de almacenamiento de datos estructurados, semi-estructurados y no estructurados.
-
En cuanto al procesamiento de datos, los Data Lakes suelen necesitar un servicio separado como Spark. Los Data Warehouses aportan este servicio de procesamiento.
Componentes de un Data Lake ¶
-
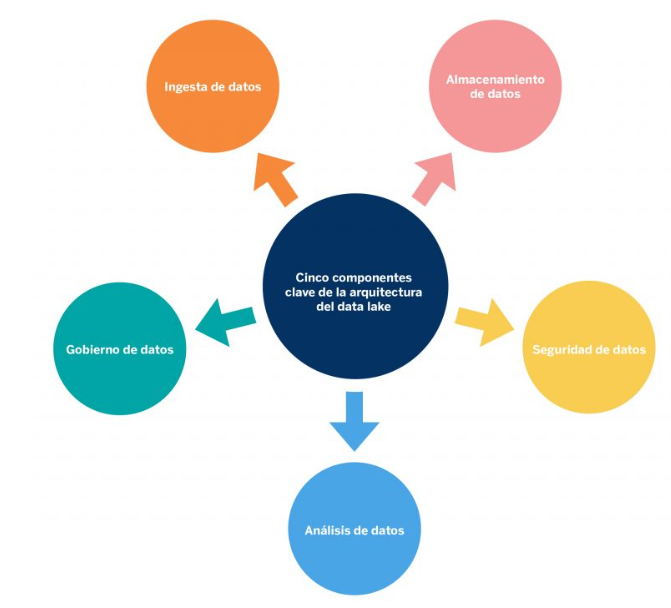
Ingesta de datos: Un sistema de capas de ingesta fácilmente escalable que extrae datos de fuentes diversas, incluidas páginas web, aplicaciones móviles, redes sociales, dispositivos IoT y sistemas de gestión de datos existentes. Debe ser flexible para ejecutarse en diferentes modos (por lotes (batch), de una única vez o en tiempo real) y admitir cualquier tipo de datos y fuentes de datos nuevas.
-
Almacenamiento de datos: Un sistema de almacenamiento de datos debe ser capaz de almacenar y tratar datos sin procesar, así como soportar sistemas de cifrado y compresión manteniendo su eficiencia en términos de costes.
-
Seguridad en los datos: Deben ofrecer máxima seguridad, utilizando sistemas de autenticación y autorización, así como niveles de acceso basado en roles, protección de datos, etc.
-
Análisis de datos: Una vez realizada la ingesta, los datos deben poder ser analizados de manera ágil y eficiente utilizando herramientas de análisis de datos y aprendizaje automático para extraer información relevante y transferir los datos examinados a un almacén de datos.
-
Gobierno de datos: El proceso de ingesta, preparación, catalogación, integración y aceleración de consultas de datos debe simplificarse en su totalidad para garantizar un nivel de calidad de los datos para uso empresarial.
Ventajas de un Data Lake ¶
-
Data Lake ofrece a los usuarios comerciales acceso inmediato a todos los datos.
-
Los Data Lake no se limitan a relacionales o transaccionales.
-
Con un Data Lake, nunca necesitará mover los datos.
-
Data Lake acelera la entrega al permitir que las unidades de negocios pongan en marcha las aplicaciones rápidamente.
-
Ayuda completamente con la producción y la analítica avanzada.
-
Ofrece escalabilidad y flexibilidad rentables.
-
Ofrece valor a partir de tipos de datos ilimitados.
-
Reduce el costo de propiedad a largo plazo.
-
Permite el almacenamiento económico de archivos.
-
Rápidamente adaptable a los cambios.
-
La principal ventaja del Data Lake es la centralización de diferentes fuentes de contenido.
-
Los usuarios, de varios departamentos, pueden estar dispersos por todo el mundo y pueden tener acceso flexible a los datos.
Data Silos ¶
Los silos de datos ocurren cuando no existe un lugar o un sistema centralizado en el que almacenar todos los datos de la organización. Un silo, por tanto, hace más complicado descubrir nuevos datos, ya que cada uno de ellos está controlado por un departamento independiente, con diferentes políticas e incluso tecnologías.
La razón principal para la creación de data lakes en las compañías es evitar los silos de datos, que suelen producirse a causa de un crecimiento rápido y poco controlado.
Estructura de un Data Lake - Zonas ¶
No existe un modelo único de como estructurar un Data Lake, cada organización tendrá su propio conjunto de requisitos únicos. Un enfoque simple puede ser comenzar con algunas zonas genéricas (o capas).
- Raw / Bronze
Esta capa es un depósito que almacena datos en su estado original, sin filtrar ni limpiar. Puede optar por almacenarlo en formato original (como json o csv) pero puede haber escenarios en los que tenga más sentido almacenarlo en formatos comprimido y más eficientes como avro, parquet o Databricks Delta Lake. Estos datos siempre son inmutables; deben bloquearse y autorizarse como de solo lectura para cualquier consumidor (automatizado o humano). La zona se puede organizar usando una carpeta por sistema de origen, cada proceso de ingestión tiene acceso de escritura solo a su carpeta asociada.
- Cleansed / Silver
La siguiente capa se puede considerar como una zona de filtración que elimina las impurezas, pero también puede implicar un enriquecimiento.
Las actividades típicas que se encuentran en esta capa son la definición de esquemas y tipos de datos, la eliminación de columnas innecesarias y la aplicación de reglas de limpieza.
La organización de esta zona suele estar más impulsada por el negocio que por el sistema de origen; por lo general, podría ser una carpeta por proyecto. Algunos pueden considerar esta capa como una zona de prueba. Si los analistas de datos o los científicos necesitan acceder a los datos en esta capa, se les podría otorgar acceso de solo lectura.
- Curated / Gold
Esta es la capa de consumo, que está optimizada para análisis en lugar de ingesta o procesamiento de datos. Puede almacenar datos en data marts desnormalizados o esquemas en estrella.
El modelado dimensional se realiza preferiblemente utilizando herramientas como Spark o Data Factory. Esta capa puede considerarse como la única fuente de verdad. Sin embargo, no espere que esta capa sustituya a un data warehouse.
Por lo general, el rendimiento no es adecuado para dashboards o análisis interactivos. Es más adecuado para analistas internos o científicos de datos que desean ejecutar consultas ad hoc a gran escala, análisis o analíticas avanzadas que no tienen necesidades estrictas de informes urgentes.
Como los costos de almacenamiento son más bajos en el DL que en el DW, puede ser más rentable mantener datos granulares y de bajo nivel en el DL y almacenar solo datos agregados en el DW. Los activos de datos en esta zona suelen estar muy bien gobernados y bien documentados. El permiso generalmente se asigna por departamento o función y se organiza por grupo de consumidores o por data mart.
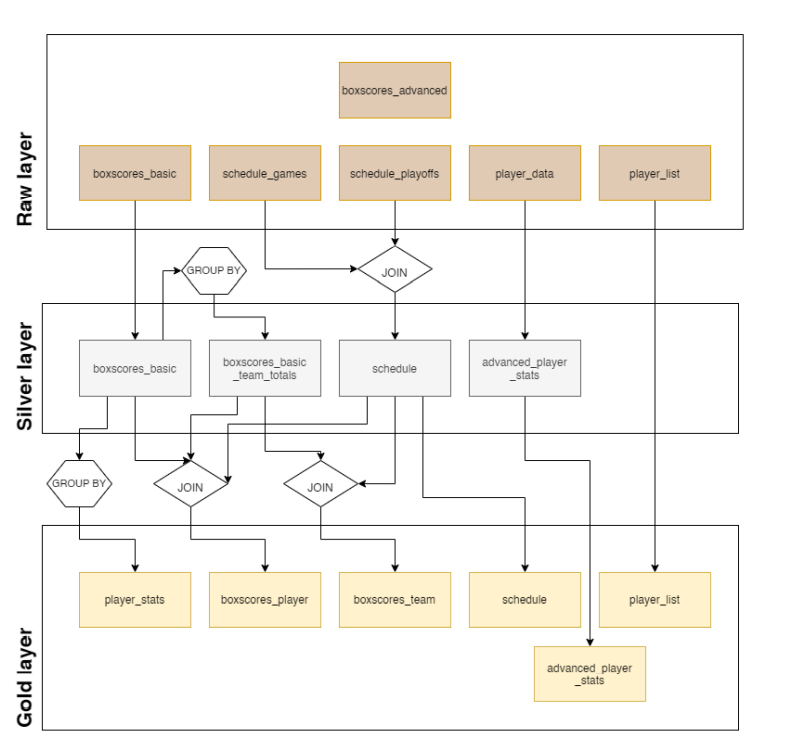
- Laboratory
Esta es la capa donde ocurre la exploración y la experimentación. Aquí, los científicos, ingenieros y analistas de datos son libres de crear prototipos e innovar, combinando sus propios conjuntos de datos. Esto es similar a la noción de análisis self-service que es útil durante la evaluación inicial.
Esta zona no sustituye a un DL de prueba o desarrollo, que sigue siendo necesario para actividades de desarrollo más rigurosas que siguen un ciclo de vida de desarrollo de software típico. Cada usuario, equipo o proyecto del DL tendrá su propia área de laboratorio a través de una carpeta, donde podrá prototipar nuevos conocimientos o análisis, antes de que se acuerde formalizarlos y operacionalizarlos a través de jobs automatizados. Los permisos en esta zona suelen ser de lectura y escritura por usuario, equipo o proyecto.
¿Cómo se puede implementar un Data Lake? ¶
Un Data Lake se puede implementar de dos maneras:
-
Data Lake Local (On Premise): implementado en "servidores propios", es decir, la propia empresa es la que se debe encargar de tareas que van desde la compra de software, instalación de hardware y software, hasta el paso de producción y mantenimiento.
-
Data Lake Cloud: tiene la ventaja de que se disminuyen los tiempos de configuración y adminitración. Sin embargo, antes de contratar este servicio, es recomendable definir cuántos datos vamos a almacenar y su tasa de crecimiento estimada. Esto nos permitirá organizar de mejor manera el aumento del tamaño y como consecuencia prevenir el quedar cortos en algún punto de los proyectos.
Plataformas para Data Lake ¶
-
AWS Data Lake:
- Amazon S3
- Amazon Redshift
- AWS Glue
-
Azure Data Lake:
- ADLS (Azure Data Lake Storage)
- HDInsight (Hadoop/Spark/Kafka)
- Azure Data Factory
-
Cloudera Data Lake:
- Tecnologías Hadoop y oopen source
- HDFS
- CDP (Cloudera Data Platform)
Data Lakehouse ¶
Une los dos conceptos, Data Warehouse y Data Lake.
-
Los dato se almacenan en un sistema de almacenamiento único (estructurados, semiestructurados y no estructurados), de bajo coste.
-
El Data Lakehouse se organiza por capas con diferentes niveles de madurez del dato, habitualmente hablamos de Raw, Silver y Gold.
-
Los datos se comienzan almacenando en su formato original, capa RAW, sin formatear ni procesar.
-
Posteriormente se convierten a formato Delta Lake o Parquet realizando las trasformaciones necesarias para almacenarlos en cada una de las capas restantes.
-
Suelen comenzar como data lakes que contienen todo tipo de dato, luego se convierten al formato Delta Lake, que permiten procesos transaccionales ACID (atomicidad, consistencia, aislamiento y durabilidad) desde almacenes de datos tradicionales.
-
Un Data Lakehouse tiene como objetivo mejorar la eficiencia mediante la construcción de un data warehouse con tecnología de data lake.